In diesem Kapitel wird gezeigt, wie man die ganzen Protokolle, insbesondere HTTP, mit Linux-Tools automatisieren kann; Wer keine Linux-Kenntnisse hat, wird dieses Kapitel nicht interressieren.
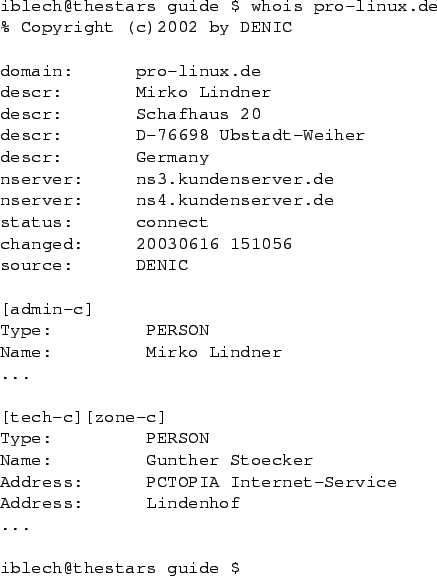
Auch wenn man mit dem Whois-Protokoll sehr viele Informationen über Domains sammeln kann, ist das manuelle auffinden des zuständigen Whois-Servers auf Dauer mühsam75.
Deswegen gibt es für gute Systeme einige Whois-Clients, die diesen Vorgang automatisieren und auch den störenden Disclaimer automatisch entfernen.
Der Client whois ist dabei besonders praktisch, da er bei vielen modernen
Distributionen gleich mitgeliefiert wird (herunterladbar von
http://www.linux.it/~md/software/). Die Bedienung ist überaus einfach
(siehe Screenshot
![[*]](crossref.png) ).
).
Das Daytime-Protokoll (beschrieben ) ist
sehr nützlich für die Synchronisation der Systemuhren vieler Rechner in einem
Netzwerk. Aber wer will schon manuell in einem größeren LAN alle Uhren stellen?
Da kann auch ein simples Shellskript eingreifen, was zum Beispiel als Cronjob76 ausgeführt werden kann:
date --set="telnet server daytime | grep :`" hwclock --systohc --utc
Die letzte Zeile synchronisiert die Systemuhr von Linux mit der RTC-Uhr77 des BIOS.
Die Automatisierung bei HTTP ist natürlich besonders interessant, da heutzutage die meisten Dinge über HTTP laufen. Man kann zum Beispiel jeden Tag eine Website herunterladen und prüfen, ob sie seit dem letzten Tag geändert wurde, und, wenn ja, sie sich automatisch per Mail zuschicken lassen. Oder man manipuliert ein bisschen78 an Votes...
Lynx, fast schon ein Klassiker, ist eigentlich nur zum text-basierten Surfen (siehe Screenshot
) gedacht, lässt sich aber auch prima automatisieren.
Um zum Beispiel einfach den Sourcecode einer Seite abzurufen, benutzt man
lynx -source http://linide.sf.net/Der Quelltext wird dann auf dem Terminal angezeigt bzw kann in Pipes weiterverarbeitet werden. Will man schon die gerenderte Version sehen, benutzt man
lynx -dump http://linide.sf.net/
Das Beispiel von oben, zu prüfen ob eine Website geändert wurde und gegebenenfalls per Mail verschicken, ist dann in Shell-Skript schnell implementiert:
OMD5="$(md5sum < /tmp/seite)" lynx -dump http://linide.sf.net/uebersicht.html > /tmp/seite [ "$OMD5" = "$(md5sum < /tmp/seite)" ] || \ mail -s Linux\ Guide < /tmp/seite
Ein GET-Request ist klar, wie im Kapitel über HTTP
beschrieben, also einfach die Parameter mit einem ? getrennt von der
eigentlichen URL lynx als Parameter übergeben.
POST-Requests sind ein bisschen schwieriger, sind aber auch sehr leicht
möglich. Um die Abbildung mit Lynx via POST umzusetzen,
verwendet man
echo "name=ingo alter=15 os=Gentoo ===" | lynx -post_data -source http://host/umfrage.phpund bekommt den Sourcecode der Ergebnisseite zurück.
Allerdings ist Lynx ein bisschen begrenzt, da er zum Beispiel nicht den Referer
(siehe ) setzen kann, Cookies nicht automatisch akzeptiert und in
einer Datei gespeichert werden können79, usf.
curl ist da schon wesentlich mächtiger. Neben der Fähigkeit, auch Dateien hochzuladen, die uns weniger interessiert, bietet curl volle Unterstützung für Cookies, GET- und POST-Requests, Location-Changing sowie den schon angesprochenen Referer.
Um die eben erwähnten Features von curl zu aktivieren, sind einige Paramater nötig:
-b /tmp/cookies$$:
Liest Cookies von /tmp/cookies$$ ein. In jedem Skript sollte als eine
der ersten Zeilen
> /tmp/cookies$$stehen. Damit wird praktisch80 eine neue Identität angelegt.
-c /tmp/cookies$$:
Schreibt neu erhaltene Cookies auf die Festplatte81.
-e referer-url;auto:
Benutzt referer-url als Referer (siehe ). Wenn das
;auto angehängt wird, arbeitet curl exakt wie ein Browser (zum Beispiel
wenn es einem Location-Header folgt).
-L:
Erlaubt curl, Location-Headern zu folgen.
-m 17:
Terminiert curl nach -o ausgabedatei:
Setzt die Ausgabedatei.
Die Standardsyntax für curl lautet also
curl -b /tmp/cookies$$ -c /tmp/cookies$$ -e referer-url;auto \ -L -m 17 -o output url
Ähnlich wie bei lynx, kann83 auch bei curl ähnlich verfahren werden:
echo "name=Ingo&alter=15&os=Gentoo" | \ curl -d @- ...Alternativ gibt es auch die Möglichkeit, von curls besserer Syntax gebrauch zu machen:
curl -d "name=Ingo" -d "alter=15" -d "os=Gentoo" ...Mir gefällt allerdings folgendes Konstrukt am Besten:
{
echo "name=Ingo"
echo "alter=15"
echo "os=Gentoo"
} | tr '\n '&' | curl -d @- ...
So behält man selbst bei langen Feldern die Übersicht.
crontab -e
festgelegt werden.
/tmp gemountet wurde
-G-Option gerade dies bietet